This case study is focused on availability management and how it fits into service delivery and support. ITIL by definition is an entire library of best practices. Progressing through the case study, some ITIL processes are covered very lightly, primarily to illustrate the inter-relationship of all the process areas. This is done to focus on availability management, not discount the other process. Every ITIL process area needs to be addressed for a complete solution.
CASE STUDY: ITIL Availability Management
About the IT Service Provider
The case study used to illustrate ITIL implementation is a service provider that self-assessments rank medium to high in readiness and moderate in integration between processes. An automated service desk (a renamed help desk) is in operation but does not have access to configuration, service level or known error resolution. Change management automation is in place but does not receive input automatically from the availability, problem and capacity management processes. Note: this case study has been sanitized’ to remove identifiable customer information.
For this case study, the focus is on implementation beginning with the availability management process. ITIL does not specify where implementation should start. Many organizations choose to focus on incident or configuration management. The techniques used in the case are adaptable to multiple process areas. The key to ITIL is the utilization of the three Ps (people, process and products). Each of these will evolve as we progress through the example.
Assigning Availability Management Activities and Responsibilities
The first task is to examine the organizational structure to begin defining and communicating ITIL responsibilities. This organization is arranged by function, with matrixed project responsibilities. This is the case study organizational chart:
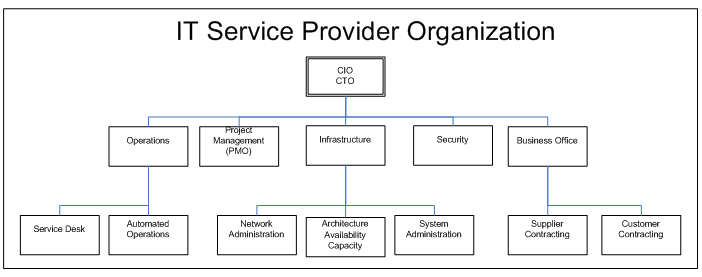
Figure 1 - Example IT Service Provider Organization
Previously a group of availability management activities was generated. These included:
- Determining availability requirements
- Identifying vital business functions
- Identifying the impact of a loss of vital business functions
- Designing for expected levels of availability
- Defining appropriate levels of security
- Producing an availability plan
- Collecting, analyzing, maintaining and reporting availability data
- Monitoring availability KPIs
- Monitoring SLA and OLA targets
- Monitoring external supplier serviceability achievements
- Conducting root cause analysis of availability incidents
From these, a list of more specific responsibilities/ tasks was generated. In this list, a suggested area of responsibility for the task has been included. This is organization dependent and typically negotiated with individual departments.
- Ensuring that the availability management procedures are reviewed semi-annually and updated as needed. [Infrastructure/Availability]
- Providing an incident management process that gathers availability management data [Automated Operations]
- Maintaining a level of expertise in current and emerging technologies supporting availability management. [Infrastructure/Availability]
- Supporting activities to increase the number of available metrics that can be included in customer SLAs. [Infrastructure/Availability]
- Conducting a gap analysis of IT project configurations and proposes solutions to limit or avoid single sources of failure. [Infrastructure/Availability]
- Implementing additional availability metrics. [Infrastructure/Availability]
- Architecting availability management concepts into projects at the earliest opportunity and ensuring availability architectures are presented to the technical review board [Infrastructure/Availability]
- Implementing automated availability management tools. [Infrastructure/Availability]
- Ensuring that system documentation is updated as needed. [Infrastructure/Availability]
- Establishing policies and procedures to collect and report availability data, such that a report of availability performance as it relates to the customer SLA and/or PSLA can be consistently prepared. [Operations]
- Operating and administering of automated availability management/monitoring tools. [Automated Operations]
- Serving as the first response staff (tier 1) for recording and resolving incidents. [Service Desk]
- Recording incoming incidents in the tracking system. [Service Desk]
- Properly classifying incidents with their availability impacts, according to established definitions. [Service Desk]
- Resolving incidents within their area of responsibility. [All/Shared]
- Recording the time service was restored on automated service tickets closed by the service desk. [Service Desk]
- Escalating the incident according to established procedures when the incident cannot be resolved. [All/Shared]
- Reviewing agreements with internal and external suppliers to ensure operational level agreements and underpinning contracts support the SLA requirements outlined in the customer contract.[Supplier Contracting]
- Reviewing customer SLA requirements as documented by the Project Manager/Customer Relations Manager (PM/CRM) to ensure availability management risk is minimized. [Customer Contracting]
- Ensuring that all systems are scanned for security vulnerabilities when system availability is restored. [Security]
- Ensuring that members of staff are aware of and follow this policy and have received availability management training for the projects they support. [CTO/CIO]
- Monitoring the progress of incidents to ensure completion, timeliness, and thoroughness. [Service Desk]
- Monitoring availability incidents to ensure rapid continuity of operation planning (COOP) implementation when availability SLAs are endangered, based on Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). [CTO/CIO]
- Obtaining the availability requirements in business terms from the customer. [PMO]
- Producing the availability plan. [PMO]
- Ensuring ongoing availability reporting to the customer. [PMO]
- Initiating action when service levels are not met. [PMO]
- Ensuring availability management procedures and requirements are reviewed and updated as needed. [PMO]
- Knowing the relevant SLAs for availability management and other metrics for specific customers. [All/Shared]
- Acknowledging, completing and documenting tasks on incidents assigned to them within established timeframes. [All/Shared]
- Ensuring that a service ticket with details regarding the incident has been opened for any incident for which they perform tasks. [Service Desk]
- Properly classifying incidents with their availability impacts, according to established definitions on service tickets they generate. [Service Desk]
- When contacted regarding an availability incident where no service ticket has been opened, they should clarify to the caller that only availability incidents recorded as a service ticket will be utilized to measure availability performance. [All/Shared]
How departments fulfill these responsibilities and complete these tasks is typically left to them. A complete delegation would include establishing Key Performance Indicators (KPIs) for each item. This level of detail is beyond the scope of this article.
Measuring Availability KPIs
Examining the fundamental availability metric, the availability of a service, requires understanding and analysis of many of the related KPIs. Service availability is a percentage of actual availability divided by agreed availability multiplied by 100 over an interval of time, such as a month or a year.
But what does it mean for a service to be available? In this case study, the organization considered three granular levels to construct their customer SLAs:
- System prompt availability
- Process availability
- Application/service availability
System prompt availability is the ability of a single host or node to respond to requests. This can be evaluated by initiating a telnet session or ICMP ping. This is a basic indicator that the system is “alive”. However, this may not indicate a system is usable. This type of metric can typically be set very close to 100%. For example, in 1998, HP announced a program called “5nines:5minutes” based on system prompt availability of 99.999% in 1998. [Gartner 1998]
Process availability is the ability to detect specific processes running on a host or node. This can be evaluated on the host without network communication using a process command such as ps’ on Unix host. The evaluation can be positive or negative. For example, the system may be considered available if a process is not running. For example, an online mainframe application does not become available until a nightly batch update is complete. If the batch update is still running, the online system is not available.
Neither system prompt nor process availability has a simple evaluation for availability in a clustered or redundant configuration. Service may be available even if one or more servers are unavailable. With system prompt or process availability metrics an evaluation, often a manual one must take place to determine if a single node or component failure would impact availability. The key question is - can customers obtain the promised service?
This enters the realm of application or service availability. For example, the Ebay.com auction site search application is handled by a cluster of 50 servers [Cockcroft 2004]. A significant number of these physical servers could be unavailable without affecting service availability. Typical ways of measuring availability in this type of environment are with robots (systems generating automated simulations of activities) or monitoring of key activity or error log files.
Integrating Availability Management Activities and Responsibilities
Availability management in ITIL is wrapped around the incident life-cycle (see Figure 4). Before any incidents occur, availability management functions take place during service planning and design. During incidents, availability metrics are gathered. After incidents occur, availability data is collected and reported. When availability data is analyzed, improvements are introduced if SLAs are not met.
In the next section, a storyboard demonstrates how people, processes and products (the three ITIL Ps), integrate together when applied to an IT service. The italicized text was previously listed in the generated list of responsibilities and tasks. This IT service is the delivery of a high-availability J2EE web application platform hosting application code developed by the customer for the Medical Records Project (MRP).
Availability Storyboard
The MRP customer requests the IT service provider to host the MRP web application. The IT service provider assigns a project manager to develop project requirements, budgets and schedules for the implementation. Because the MRP deals with medical records, high availability is a central concern, and the customer budget can support their requirements.
The project manager meets with the customer to obtain the availability requirements in business terms. The availability requirements are provided to architecture so availability management concepts are included in the system design. Availability requirements also go to customer contracts, so they can be included in the SLA and hosting charges. System documentation is updated as needed by input provided to configuration management. During the procurement phase, IT reviews supplier contracts to ensure internal and external support contracts support availability requirements. Where necessary, IT implements and monitors automated availability management tools.
With input from service level management, the PMO produces an availability plan. The MRP customer and the IT service provider have agreed to an application-level availability of 99.9%, as measured by the functions of login, access a patient record, update the patient record and logout. When an outage occurs, medical care of patients can be affected, so it has a high impact to the business. The agreed cost is six times the standard hosting rate. However, for any month where the availability is below 99.9%, the IT service provider rebates that month of hosting service charges.
The application is about to enter the production phase. This typically represents the largest amount of time in a service life-cycle. This phase is cyclical; roughly following the do-check-act steps in the Deming PDCA wheel (Figure 2).
The story resumes just prior to the availability incident. During the operation and administration of automated monitoring tools, a sensor indicates MRP is unavailable. The automated response includes opening an automated service ticket and alerting the service desk and key support personnel (including suppliers). The service desk responds as tier 1 support, verifies the specific customer’s availability SLA is impacted, confirms through change management that the outage is unplanned, validates the outage and assigns an impact according to established definitions. In preparation for service restoration activities, the last change applied to the application components is researched and documented in the incident ticket. For the MRP customer, these actions by the service desk are all that is required before escalation to the next tier of support. Despite this ending the first tier of support, the service desk continues as the central contact point regarding the incident.
Contracts with internal and external suppliers require a fifteen-minute response to an established conference bridge when the incident impacts the MRP availability SLA. As participants arrive, the service desk provides information regarding the outage, ticket and change, as well as coordinates activities by support staff. The service desk administers a service restoration checklist to triage and isolate the source of the outage. CTO/CIO staff monitors the outage resolution to assess whether the incident can be resolved within the SLA parameters and to evaluate the implementation of COOP/DR plans. Members of the support staff acknowledge complete and document tasks that are assigned to them. As tasks are completed, the outage is regularly validated using the method that originally indicated the outage. When service is restored, the service desk collects and records availability data and reassigns the ticket to the problem management function for root cause analysis. Security scans the configuration for security vulnerabilities that may have been introduced through the resolution process.
If availability data shows the MRP service had an outage(s) of 30 minutes this month, the IT service provider has met the availability component of the SLA. In the m_onthly availability report, the PMO calculates an availability of 99.93_, based on providing 43,170 service minutes out of 43,200 service minutes available, with an agreed availability of 99.9%.
On the other hand, if availability data shows the MRP service had an outage(s) of 45 minutes this month, the IT service provider has not met the availability component of the SLA. In the monthly availability report, the PMO calculates an availability of 99.89, based on providing 43,155 service minutes out of 43,200 service minutes available, with an agreed availability of 99.9%.
When availability service levels are not met, the PMO initiates action to improve availability. This may include directing architecture to conduct a system gap analysis to determine if the system can be enhanced technically or ensuring staff have sufficient training in availability policies and are aware of customer SLAs. The specific action is usually determined by analysis of additional availability/outage metrics, such as how long it takes to diagnose or repair the underlying problem (MTTR) or how often an outage occurs (MTBF).
Summary
The primary objective of this article was to move beyond the framework provided by ITIL. A general understanding of the ITIL framework is introduced by the topics covered in the ITIL Foundation certification. Moving beyond requires entering the Practitioner level, beginning to design specific ITIL processes, in this case, availability management. When designing and performing ITIL process area tasks, an understanding of the breadth of all the ITIL processes. This is the area recognized by the ITIL Manager’s Certificate.
In developing this topic, it was necessary to provide some ITIL background at the foundation level. This was followed by some background and practice within the availability management process. Using a real-world example of an IT service provider, customer and IT service, an ITIL availability management process was constructed. Once the process was designed, it was illustrated using a storyboard technique with activities from many of the ITIL processes involved to illustrate the interaction between them.